Veeam Repository Best Practices – Part 3
With Part 1 and Part 2 in the bag, it’s time to wrap up this series. In Part 3 we’ll be covering some optimal settings for your backup jobs, as well steps that you should take to protect your repository from real-world dangers. I will also touch on the new Scale-Out Backup Repository feature towards the end of this post.
Backup Jobs

Knowing the difference between the backup job types is imperative. I was in a situation a little while back where my backup speeds dropped dramatically (like down to the single digit MB/s). In the end, it turned out that the storage was being hammered due to some recent changes. In my case, the jobs were older and were using reverse incrementals. Switching it to a forever forward (Incremental) job instantly increased the speeds and shrank the backup window.
So why the speed increase when moving from a reverse incremental? A reverse incremental performs 3 IOPS per block – see this page for a great visual explanation of the process. The 3 IOPS consist of the following operations:
- the new block is injected into the backup file;
- the block it is replacing is read and,
- the read block (from step 2) is injected into the rollback file.
Forever forward backups, on the other hand, are 2 IOPS per block: one read from the VBK file, and one write to the VIB file. Writes to the repository are also sequential in nature, which helps improve overall IO.

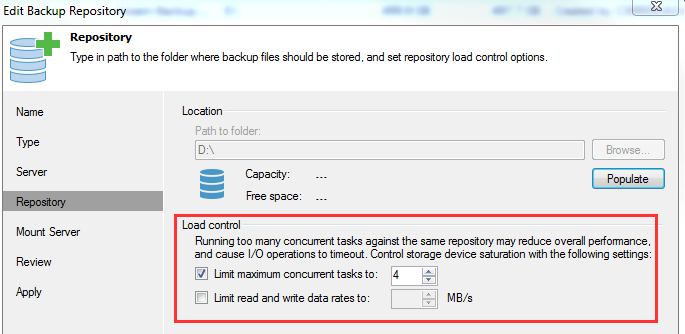
Regardless of which type of job you use, remember to keep an eye on your repository. If you happen to have production systems running on the same repository that you are backing up to, you might see some degradation of service. You can limit the load on the repository by configuring a max concurrent tasks threshold, or a max read/write threshold.
As for the actual job, it is recommended to keep the Dedupe option turned on. The same goes for compression. Generally speaking, the Optimal setting will give you the best results without doing in-depth testing with your storage. There is an option to ‘Decompress before storing’ which you will want to understand.
If you are using a deduplicating storage appliance, check out this page: https://helpcenter.veeam.com/backup/hyperv/repository_repository.html. The short version is that if you keep your data compressed, there will be fewer matching blocks, and therefore, you will get poor dedupe ratios.
If you are just tossing this data onto a JBOD or DAS that doesn’t dedupe, feel free to leave the data compressed to save space, but this isn’t recommended from a performance perspective either. The actual act of decompressing the data has a very low CPU overhead. This low overhead shouldn’t really impact backup jobs, but might yield improvements in speed for restore jobs.
Protecting the repository & making data available
Whether it is primary or secondary storage, hardware-based snapshot replication is not recommended. At first, I found this odd as from what I have experienced, SAN-based replication tends to be very efficient. The recommendation is to use a Backup Copy Job. Why? Simply put, the Backup Copy Job will perform a health check on the file as it is being copied. If a bad block is found, the job will fix it on the fly. With a hardware based solution, a bad block would just be replicated, and you would hate to find that during a restore.
The backup copy job also really opens the door to offsite options. You are no longer restricted to having similar hardware at a remote location. A lot of organizations don’t have similar SANs in offsite locations that they can replicate to. Using the backup copy job, you can move copies of your backups offsite to anything that is a Veeam repository, including remote USB hard drives (more on this below).
Don’t lose sight of what is actually in there – if you find yourself in times of trouble, the last thing you need is for your repository to crap out on you, or be unusable. It isn’t just poor hardware that can cause trouble. Think about securing those files. Setup special service accounts and load these credentials into the Veeam backup job. If you keep these credentials secure, you are protecting yourself against malicious admins, and things like Cryptolocker. Just imagine the feeling of needing to do a restore because of cryptolocker, only to find that the share was mounted somewhere and all of your backups are encrypted.

Along those lines, also, consider rotating media. You can setup a repository to be backed by rotated hard drives. This allows you to let Veeam know that there may not always be a hard drive there to back up to, so don’t freak out. A simple example would be a USB hard drive attached to something as simple as your desktop. Set it up as rotating media and swap the drives out according to your schedule. Keeping these drives offline also protects you against these ‘online’ threats, such as Cryptolocker.
Scale-Out Backup Repositories (SOBR)
Scale-Out Backup Repositories are a new feature in V9. I haven’t used them in production yet (they would have been super handy a couple of years ago), but consider them when planning your architecture. These can be leveraged for performance and storage efficiency. There was a great post recently on Twitter where someone illustrated the difference in performance that a SoBR can make.
https://twitter.com/lycwolf/status/707982849467555840
In a nutshell, SOBR allows you to take multiple chunks of storage (known as extents), and meld them together into one ‘virtual’ repository. Veeam manages all aspects of the extents based on things like available capacity and performance. For more on setting up SoBR, check out my Step-By-Step post.
Wrapping Up
Hopefully, there was some good info spread out over these posts. I have mentioned it before, and I’ll mention it again: be sure to check out the free VeeamOn videos, the Veeam forums, and the free Veeam whitepapers. Just about all of the information in these posts came from there. The goal of these posts was to consolidate a lot of this stuff. I had a hard time gathering the information in the first place and what better way to document it then with a blog post?



Pingback: Veeam Repository Best Practices – Part 2 | Matt That IT Guy