
 I have been spending some time over the last little bit trying to put together a new repository for my Veeam backups. Finding a simple set of recommendations hasn’t been easy, though, largely due to the fact that every environment is different.
I have been spending some time over the last little bit trying to put together a new repository for my Veeam backups. Finding a simple set of recommendations hasn’t been easy, though, largely due to the fact that every environment is different.
Despite there being no simple ’this is what you should use for every install’, I took the effort to review a lot of material and put some notes together. A lot of the details were from VeeamOn videos, the Veeam forum, or from their various Veeam eBooks. After going through all of that, I think I have come up with a good solution that fits my environment.
The first step to figuring out what your repository should look like is to figure out what you need. Consider things like the following:
- how much retention is needed;
- what do your backup windows look like;
- and how important is restore performance.
Ultimately a lot of this designing comes down to cost vs. performance. When budget becomes an issue I usually suggest figuring out the current RPO and RTO and advise management of what these targets are. If things are good, great no changes are needed. But be sure to put a time on how long you can maintain those numbers based on growth. If things need improvement, size appropriately and figure out the cost to scale.
Hardware & Protocols
Physical hardware is always recommended (as opposed to storing the backups on a VM). There are two common reasons for this:
- Performance tends to be better on bare metal hardware and
- It removes a layer of abstraction.
In the event that you are in recovery mode, you don’t want to have to rebuild a hypervisor so you can get a VM going in order to do a restore. It also presents a bit of a chicken or the egg problem: how do you handle your VM restore if your VM contains the backup files?
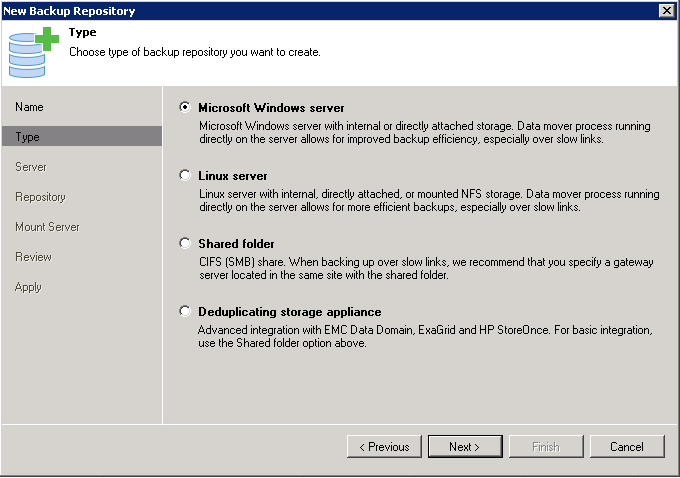 On the low-end side, you probably want to look at using older servers instead of low-end NAS devices. Most NAS devices aren’t typically CPU heavy, and you might also run into issues with disk performance. A perfect low-end server would be one that you can toss a bunch of disk into. Ideally, you will want it to be running Windows or Linux so that you can install the Veeam agents on it. These agents assist with the efficiency of the backups.
On the low-end side, you probably want to look at using older servers instead of low-end NAS devices. Most NAS devices aren’t typically CPU heavy, and you might also run into issues with disk performance. A perfect low-end server would be one that you can toss a bunch of disk into. Ideally, you will want it to be running Windows or Linux so that you can install the Veeam agents on it. These agents assist with the efficiency of the backups.
If you are stuck with a NAS, chances are you’ll need to use a CIFS share, which is not recommended ( note that chances are it isn’t actually CIFS, but SMB). CIFS tends to be a very ‘chatty’ protocol and doesn’t provide good performance. If you need an alternative, look at mounting the storage via iSCSI into the guest OS. This method may provide you better performance that CIFS, but can also introduce complexity. Things like targets, initiators, and authentication should all be well documented in case you need reconfigure access to the LUN. Another hack to avoid CIFS is to mount the share as NFS on a Linux box and install the Veeam agents on that Linux machine.
Regardless of which storage you go with, you’ll want to see if there are any vendor-specific integrations that Veeam leverages. Things like utilizing your SANs snapshotting capability (vs. VMware’s) can help ease the load.
Deduplication
You will also want to avoid deduplicating appliances for primary storage. Why? Well, these devices will constantly be de-duping your backups, which doesn’t work so well if Veeam needs them for things like reverse-incrementals or synthetic fulls. Deduplication is fantastic for secondary storage though as the data tends to be ‘colder’.
If you do need to run dedupe on your primary storage, I have a tip. Try to only dedupe files older than 8 days (assuming you do a full every 7 days). This will usually mean that when it comes time to perform a synthetic full (or just reading recent files in general), you won’t have the overhead of dedupe to worry about. Along these lines, you should also take into consideration jobs that use backup transformations. If the data has been deduped (and compressed), there will be a lot of overhead when searching for and uncompressing the blocks that you need. In this case, an Active Full backup will likely give you far better results than creating a synthetic full.
In part 2 of this series, I’ll be covering using Windows as a repository, as well as RAID best practices.