
 I recently had the opportunity to sit in on a ‘cozy’ conference call hosted by Tintri. I say cozy because excluding Tintri staff, there were less than 10 of us customers and users who were invited. The purpose was to give us a demo of some of Tintri’s recently announced products and features, and the small size definitely gave it a nice touch. There was also no shortage of talent on the presentation end to take us through these new additions.
I recently had the opportunity to sit in on a ‘cozy’ conference call hosted by Tintri. I say cozy because excluding Tintri staff, there were less than 10 of us customers and users who were invited. The purpose was to give us a demo of some of Tintri’s recently announced products and features, and the small size definitely gave it a nice touch. There was also no shortage of talent on the presentation end to take us through these new additions.
We ended up covering four of their newest offerings:
- Synchronous Replication
- vRealize Orchestrator Plugin
- Chat Ops
- Tintri S3 Connector
For the sake of not dragging on too long, I’m just going to focus on the Synchronous Replication feature in this post. I’ll likely cover some of the other content in future posts as I do have some thoughts on them.
Synchronous replication is a great new feature which I first heard about at VMWorld. The concept behind it is that when you go to write data to your storage, it gets written to multiple arrays at once. Traditionally, storage arrays would write data to a primary array and then replicate it out to a secondary array. The problem with this method is that a) your primary array is still a single point of failure and b) you are sometimes limited to a replication window of like 5 minutes minimum.
Tintri has architected this solution to not only bypass the single point of failure, but it also allows you to have an RPO (recovery point objective) of 0. Because data is written simultaneously to multiple arrays, if your ‘primary’ array is lost, the secondary array in the replication group will already contain the same data.
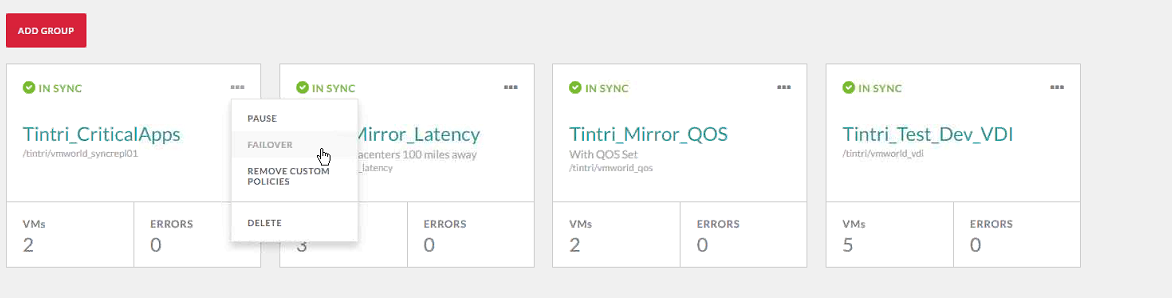
Initiating a failover is literally just a click away.
So, what are the nuts and bolts of this feature? Tintri VMStores are added into a service group, each with their own IP address, but then an IP address is assigned to the group and used for the datastore. If you end up having to perform a failover, that datastore address is shifted to the available VMStore. Expected failover times range from 1 second or less, up to 10 seconds in severe cases. As for manually initiating a failover, it literally is just a matter of selecting the service group, and choosing Failover from the context menu. From a high level, that is how it works – nice and simple.
Because Tintri is ‘VM Aware Storage’, you can setup replication based on your VMs / application groups. This means that you don’t need to replicate whole LUNs like other solutions, potentially copying over virtual machines which aren’t needed.
The requirements for the solution are also quite reasonable. Both the T800 series and T5000 series of VMStores are supported, and what I found very interesting is that a hybrid array and an all flash array can both be part of the same service group. That makes for not only some nice backwards compatibility but also leverages what might be older hardware for DR purposes.
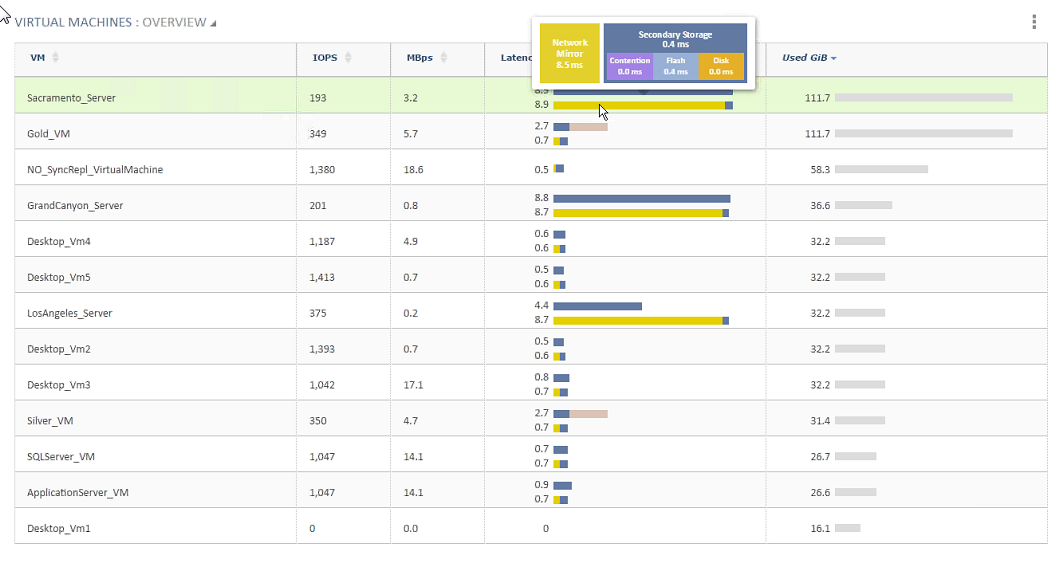
Tintri let’s you see through the stack to identify latency.
What about latency? You’ll see a lot of the marketing papers list replication for distances ‘up to 100km’. In truth, the more important factor is latency. Ideally, if you can keep your latency between VMStores under 10ms, then you should be good to go. In true Tintri fashion, you can also log into their dashboard and see how much latency there is on the replicated VM from the replication.
Closing Thoughts
I like what I saw. One of the biggest draws I had towards Tintri when I did my last round of storage shopping was its simplicity. Their interfaces have always been straightforward, their visualization of data has been clear and easy to read, and the analytics have been more than helpful with planning. This all still holds very true with the asynchronous replication.
If you find yourself in a situation where you want to failover your storage, you don’t want to be searching around for commands, or get lost in a complicated GUI. Tintri addresses this with a single click. Similarly, you’ll want to know how your virtual machines are faring on their new home. With the Global Center dashboard, you can see this at a glimpse and identify what, if any problems, need to be addressed. Tintri’s synchronous replication is yet another example of how they intend to make storage simple.
More information can be found on Tintri’s site, here.