Tech Field Day 12 Primer: DriveScale
 DriveScale will be presenting at Tech Field Day 12, and it looks like they will have a lot to share. It took me quite a few reads to finally wrap my head around what they do, but I think I have a clear picture now.
DriveScale will be presenting at Tech Field Day 12, and it looks like they will have a lot to share. It took me quite a few reads to finally wrap my head around what they do, but I think I have a clear picture now.
Based out of Sunnyvale CA, and founded in 2013 by some extremely smart folks, DriveScale only came out of stealth in May of this year. At the same time, they announced $15 million in Series A funding. One of the investors includes Foxconn (via one its subsidiaries – Ingrasys Technology), who are the largest contract electronics manufacturer in the world. I imagine that can be a pretty lucrative deal if things pan out.
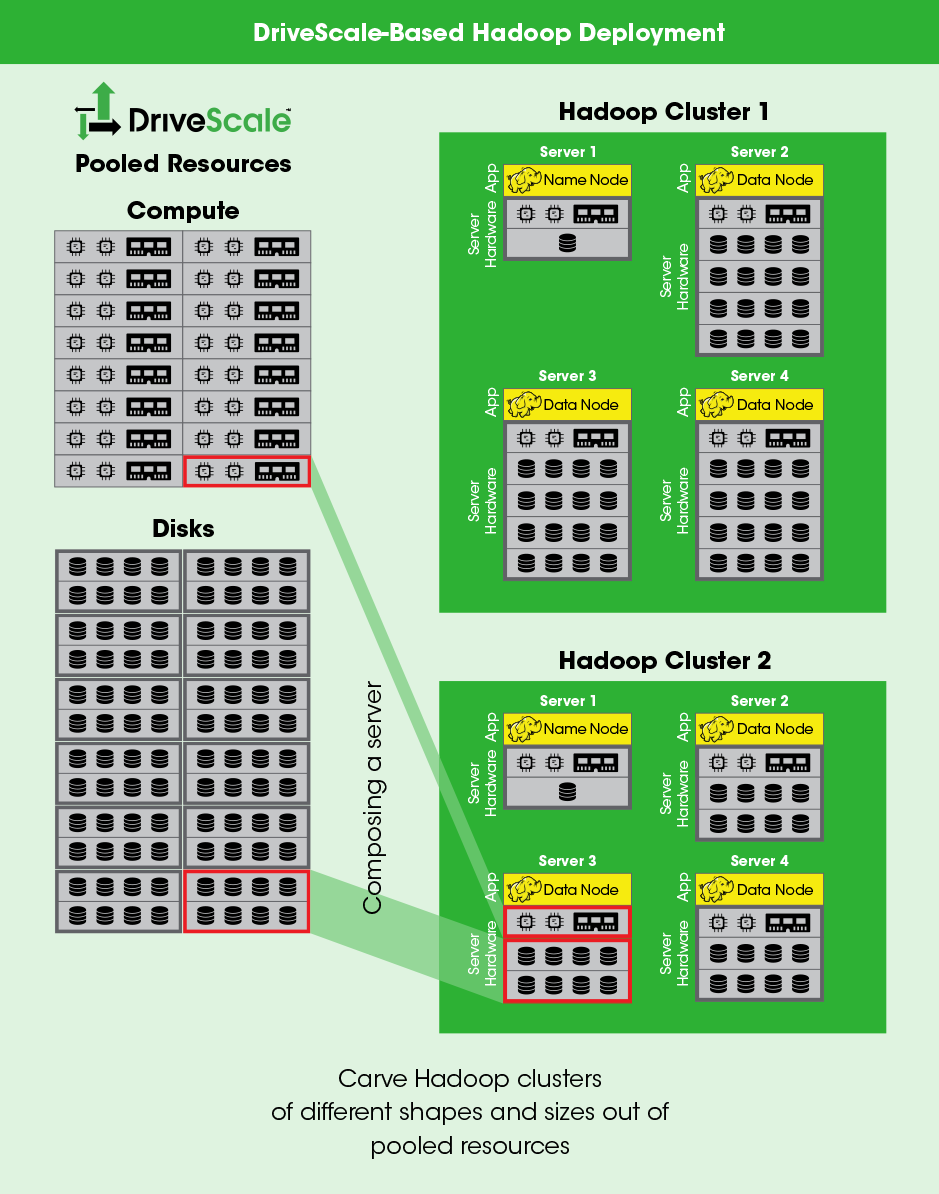
DriveScale’s is a ‘rack scale architecture’ whose target is primarily large environments that have Big Data needs. Most commonly, this would be environments that are using technologies such as Hadoop. What it aims to do, is allow administrators to rebalance and reallocate infrastructure when needed. It does this in part by adding a layer of abstraction to existing compute and storage resources.
The system is controlled by the DriveScale Management Server, which is software that runs on Linux-based machines. The Management Server is responsible for coordinating actions on the nodes, and this is accomplished with an agent that is installed on the compute nodes. Lastly, there are DriveScale Adapters (physical hardware), which are Ethernet to SAS bridges. Each adapter wields a pair of 10 GbE ports, as well as a pair of 12Gb Mini-SAS HD interfaces.
These adapters come in a 1U chassis format, which houses four nodes per chassis. With this configuration, each chassis is fully redundant with regards to power and connectivity. With all of those network interfaces, you have a theoretical throughput of 80Gb per chassis … good for moving data in a hurry. These adapters can then connect to a JBOD array, which you can fill with off the shelf disks.
 Hopefully, this is starting to paint the picture – you have a management piece, which talks to agents, which controls compute and storage for each endpoint. With this management piece, you can then start allocating (or deallocating) resources as you see fit, across multiple racks. Because of the ability to leverage commodity storage and compute, this could make for an attractive solution as customers can leverage existing investments in their datacenter. Along those lines, the management interface is available via a GUI, however, it also supports RESTful API calls. We are definitely seeing RESTful API support becoming a golden standard for vendors and in use cases such as DriveScale’s it makes complete sense.
Hopefully, this is starting to paint the picture – you have a management piece, which talks to agents, which controls compute and storage for each endpoint. With this management piece, you can then start allocating (or deallocating) resources as you see fit, across multiple racks. Because of the ability to leverage commodity storage and compute, this could make for an attractive solution as customers can leverage existing investments in their datacenter. Along those lines, the management interface is available via a GUI, however, it also supports RESTful API calls. We are definitely seeing RESTful API support becoming a golden standard for vendors and in use cases such as DriveScale’s it makes complete sense.
I’m looking forward to hearing what they will bring to Tech Field Day 12. I’d like to touch on some of the storage stuff (e.g. how does disk / data redundancy work, does it use some sort of proprietary file system, is SSD or hybrid supported, etc.), but I’m also looking forward to just learning more about how the product works.
Drive scale will be presenting Wednesday, November 16th at 11AM local time. Be sure to tune into the live stream at TechFieldDay.com.
Disclaimer: I was invited to participate in Tech Field Day as a delegate. All of my expenses, including food, transportation, and lodging are being covered by Gestalt IT. I did not receive any compensation to write this post, nor was I requested to write this post. Anything written above was on my own accord.



Pingback: Tech Field Day 12 Primer: DriveScale - Tech Field Day
Pingback: Managing & Scaling Big Data with DriveScale | Matt That IT Guy