
 Disaster Recovery is something that can be critical to every business, but not every business has a good DR plan. Heck, I would be willing to bet that a lot of SMBs don’t even have a plan that is made up of much more than “fix the problem”. A large reason for this is designing a good, versatile DR environment is not cheap. Not every organization has the money to lay out for equipment, facilities, maintenance, etc.
Disaster Recovery is something that can be critical to every business, but not every business has a good DR plan. Heck, I would be willing to bet that a lot of SMBs don’t even have a plan that is made up of much more than “fix the problem”. A large reason for this is designing a good, versatile DR environment is not cheap. Not every organization has the money to lay out for equipment, facilities, maintenance, etc.
Situations like this have helped create the Disaster Recovery As A Service (DRaaS) market. Instead of being on the hook for all those capital costs, you can turn it into an operating cost. Depending on the solution you go with, you may need to work with a local partner. In that case, they can hopefully do a lot of the heavy lifting, implementation, and maintenance. The downsides here will likely be costs (lots of consulting hours) and being locked-in with that partner. The other option is going to a public cloud, which presents its own challenges in terms of new technologies, managing access, and refactoring applications to work with “the cloud”.
Scale Computing has attempted to tackle this problem with its HC3 Cloud Unity Platform.
LEVEAGING GOOGLE CLOUD
As a reminder, HC3 is Scale Computing’s own KVM-based hypervisor (check out my Primer post to get fully up to speed). HC3 Cloud Unity is a full-featured HC3 Hypervisor instance, running in the cloud. Scale Computing has partnered with Google Cloud to offer a nested hypervisor solution for DRaaS purposes. One of the strengths right out of the gate is in the interface. Because it is a nested HC3 environment, it is literally the same hypervisor that Scale Computing admins know and administer. Not only is there no need to train staff on a separate system, you also don’t need to worry about compatibility issues.
One facet that really stood out to me was the network connectivity between your on-premises environment and your GCP instance. In order to bridge the networks VXLANs are used. As a quick refresher/primer for non-networking folks, a VXLAN runs at layer 3 of the OSI model. It allows you to share subnets across multiple locations. For example, my local office can stretch to my branch office so that both run on 10.0.0.0/24.
Why is this cool? Well, at least a couple of reasons stand out to me. One, I don’t need to worry about re-IPing all my workloads in the event of a fail-over. If I just need to a do a partial failover (e.g. I lose one out of three racks), then I don’t need to setup funky routing rules. Two, this also means that “remote” traffic can come back through my network. If I need to run auditing or compliance tools on network traffic, having my remote hosts still go through my local tools for internet access is a huge bonus.
COOL, BUT DOES IT WORK?
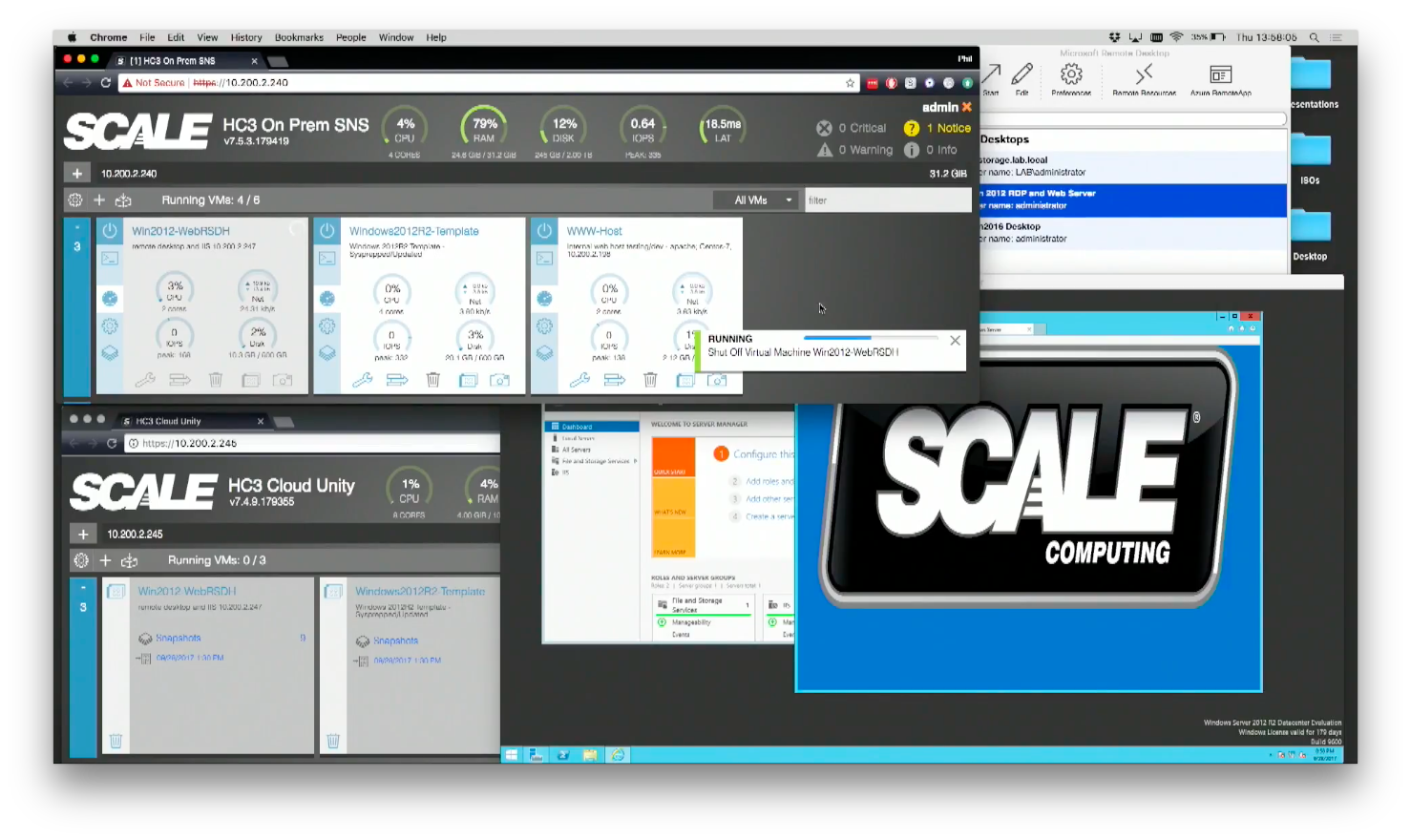 In a word, yes. In order to keep costs down, a smaller passive instance of the HC3 is running in Google Cloud. Once your organization declares a DR event, that instance is reconfigured and rebooted and it turns into a full instance, which is sized to support your workload. Once the instance is up and running, your failed over VMs will be running on Google Cloud. Through the magic of the above-mentioned VXLANs, it will appear as though your machines are local.
In a word, yes. In order to keep costs down, a smaller passive instance of the HC3 is running in Google Cloud. Once your organization declares a DR event, that instance is reconfigured and rebooted and it turns into a full instance, which is sized to support your workload. Once the instance is up and running, your failed over VMs will be running on Google Cloud. Through the magic of the above-mentioned VXLANs, it will appear as though your machines are local.
During our visit, Scale Computing wanted to show us that they were serious by doing a live demo. The hardware consisted of a Scale Computing chassis running a workload, a GCP instance, and an Intel NUC Skull Canyon running the Cloud Unity Gateway. That last component is responsible for on-premises VXLAN endpoint. With a workload running on the Scale Computing node, the power was yanked. The Intel NUC was then plugged in and turned on. After a few moments, we saw the workload come back to life, running from GCP, but accessible via its local IP Address.
FINAL THOUGHTS
As a bit of background, Scale Computing has had two (yes, two) fires in their office. After going through their own disasters, I would hazard a guess that they knew what organizations would want in a DRaaS offering. Pricing starts at $1000 / month for 5TB of storage. This also includes 12 days of DR mode testing. Having a DR plan is great, but until it is tested, it is unproven. Having this true “value add” in the offering shows that this package has customers in mind.
When compared to other solutions on the market, it is lacking in orchestration. For smaller environments, this may be a non-issue. For larger environments where dependencies are everywhere, this could be a struggling point. The good news it that an API is in the plans, which will open the door to solving this problem.
You can catch all of Scale Computing’s sessions at the Tech Field Day webpage. Cloud Unity is currently available for Beta testing. General Availability will be in Q4 2017.
Disclaimer: I was invited to participate in Tech Field Day as a delegate. All of my expenses, including food, transportation, and lodging were covered by Gestalt IT. I did not receive any compensation to write this post, nor was I requested to write this post. Anything written above was on my own accord.