
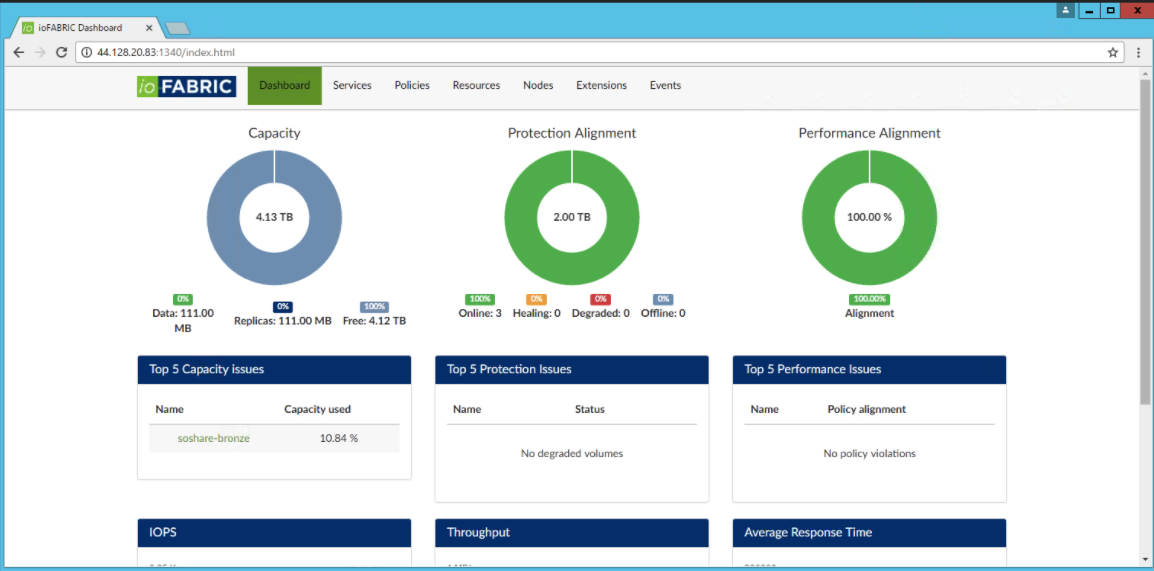
A glimpse of IOFabric’s dashboard
Trevor Pott recently introduced me to some of the fine folks at IOFabric and suggested that I have chat with them. Going into the call, I didn’t know a heck of a lot about their flagship product, Vicinity. I did a bit of research and gathered that Vicinity allows you to use existing storage and manage it via one interface. It turns out that is only part of the picture. Note that this is not any sort of sponsored post, and I was not compensated in any way to write this, but rather it is a cool product that I thought I would share. Also, writing helps me understand and digest information.
BACK TO THOSE ISLANDS OF STORAGE
Most, if not all of us are familiar with the concept of islands of storage. You might have a SAN that is %90 full, and maybe a JBOD that is %10 full, but there is no easy way to pool that storage together. Some enterprise storage vendors have options to let you manage these things from a single interface (assuming it is all their own storage), and in some cases, you can pool the resources. But what happens if you have multiple manufacturers or even multiple product lines from the same vendor?
IOFabric saw this problem and decided to fix it. Cool! You can now have all of your storage in one pool for greater efficiency! Well, that’s just the tip of the ice cube (because you need a fairly big pool in order to fit the tip of an iceberg). What Vicinity does is it lets you take any existing storage (SAN, NAS, JBOD, S3 or even RAM), and ingest it, at which point it shows up as available storage to be consumed.
THE NUTS & BOLTS
To get started, Vicinity runs on nodes, which can be a virtual appliance running on KVM, VMware, or Hyper-V, or it can be bare metal running on Linux. You’ll need at least two data nodes to get started, and one control node. As the names imply, the data nodes store the data on them, whereas the control node is actually what orchestrates all the magic. The two node minimum for the data nodes is also a requirement for data protection. By default two copies of the data are kept on separate nodes; note that this isn’t RAID (with parity bits) but rather two actual copies of the data. If the control node goes down, things will keep humming along, but you will loose that ‘single pane of glass’ view.
Once you get those setup, you can start ingesting storage for use. As an example, if you have some spinning disk sitting in a NAS, some unused SSD sitting in a SAN, and a bunch of available RAM sitting in a bare metal box, you can ingest them all into Vicinity. From there, you can share it out via iSCSI and mount it to wherever you need it. Consolidating the available data is just the first step - next we set up policies.
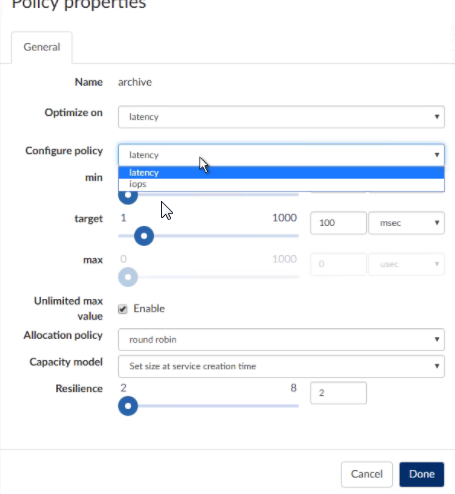 Policies are defined based on IOPS or latency and are applied to the workload. The example that came up was running analysis on a database - depending on the dataset size, this could take awhile. If we set up a policy, we can set a target as well as minimum and maximum values for either IOPS or latency. If this policy is violated (e.g. the latency is too high), we’ll get alerted. OK, kind of like QoS. But, say we know that every Friday afternoon Marketing runs a report to crunch data for the week, we can have an extension (essentially a scripted task) that runs to automatically tier this workload to RAM and then tier it back down to SSD or spinning disk.
Policies are defined based on IOPS or latency and are applied to the workload. The example that came up was running analysis on a database - depending on the dataset size, this could take awhile. If we set up a policy, we can set a target as well as minimum and maximum values for either IOPS or latency. If this policy is violated (e.g. the latency is too high), we’ll get alerted. OK, kind of like QoS. But, say we know that every Friday afternoon Marketing runs a report to crunch data for the week, we can have an extension (essentially a scripted task) that runs to automatically tier this workload to RAM and then tier it back down to SSD or spinning disk.
Some of you might cringe at the thought of running a workload in non-persistent memory. In the case of a read-only database for analytical purposes, there likely isn’t much risk. But remember above where I mentioned that data is stored on at least two nodes? Well, in this case, you might have the ‘primary’ workload running in RAM while the ‘backup copy’ is sitting on a lower tier (such as SSD or spinning disk). The point that I am trying to highlight isn’t the data protection, but rather how you can customize workloads within the system.
Snapshots are supported as well, and they can be shipped off to another node and then mounted. Where this might come in handy is if you have a bunch of archived data that is rarely touched. Say you need to recover a file from an archive - traditionally that might involve tape, which can take some time (between actual read times and potentially the need to go offsite). With Vicinity, you could just as easily ship those snapshots to an S3 data store somewhere (or even just some storage at a branch office), mount the snapshot, and find the data that you are looking for. Another option for archiving is creating a policy that auto-ages data and moves it offite for archiving.
VALUE PROPOSITION & USE CASES
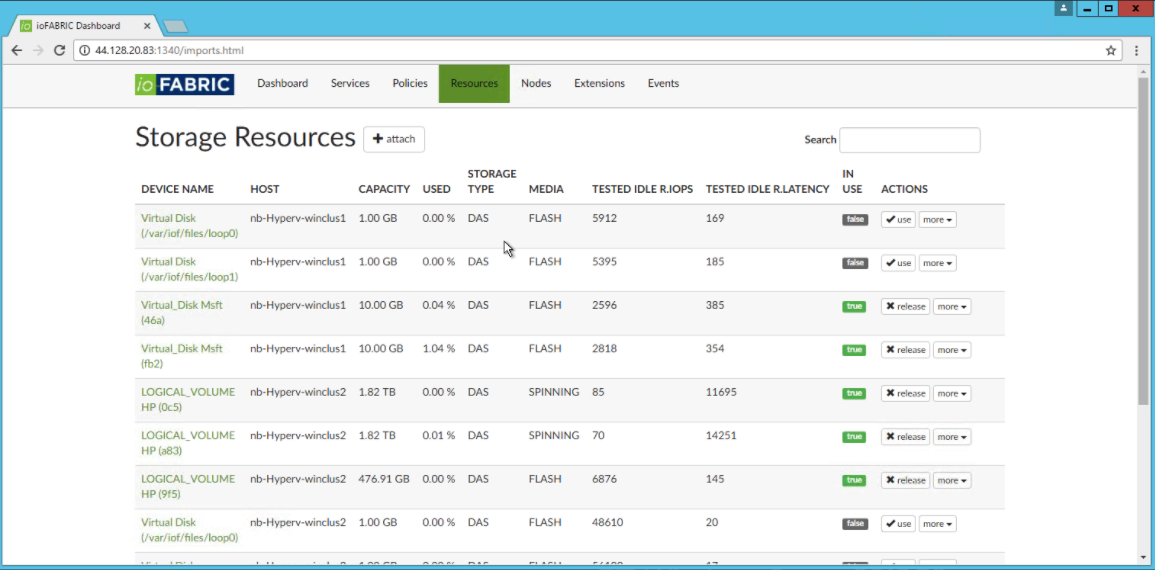 One of the first things that peaked my interest was the ability to consolidate all of my storage into one ‘chunk’, regardless of vendor or location. This lets you leverage older hardware that may not be up to snuff for production workloads, but may still be fine for low-performance applications. In this case, you’ll still need to worry about the physical shape of the hardware (e.g. dying hard drives or controllers), but with the built-in data protection, at least some of those worries should be eased. It will also let you use storage from devices that may have otherwise been junked - for example if you have an old 10 TB SAN that is too small from a capacity perspective. You can now take those 10 TB and lump it together into a larger pool.
One of the first things that peaked my interest was the ability to consolidate all of my storage into one ‘chunk’, regardless of vendor or location. This lets you leverage older hardware that may not be up to snuff for production workloads, but may still be fine for low-performance applications. In this case, you’ll still need to worry about the physical shape of the hardware (e.g. dying hard drives or controllers), but with the built-in data protection, at least some of those worries should be eased. It will also let you use storage from devices that may have otherwise been junked - for example if you have an old 10 TB SAN that is too small from a capacity perspective. You can now take those 10 TB and lump it together into a larger pool.
As for use cases, there are many. On-site archiving to older, slower storage, or maybe even completely offsite via its S3 capabilities. What about for predicted high-use of VMs? If I have a VM that I know will be busy the last day of every month, I can just run a Vicinity extension to take care of the auto-tiering, all without needing to do any sort of storage vMotion. What if I am running low on capacity, or performance? I can grab some storage from whichever vendor I choose and add it into the pool for use. This might be especially useful for those one-offs where I might need 128GB of RAM to run a workload just once - I can hop onto Newegg, order the RAM, and ingest it into the pool.
SUMMARY
This is an interesting product - it isn’t just a matter of managing storage better, it is a very much a matter of leveraging your storage (capacity and performance) better. IOFabric will be introducing a hardware appliance, but the software version will continue on as well. Currently, compression, deduplication, and caching are not supported, however, there is a newer version slated for release in the New Year which will bring those features. You can find out more at IOFabric’s web site. I’m hoping to dig deeper into IOFabric in the future as today was just a scratch of the surface.